
Faster Spark Was the Goal. A Simpler Spark Came With It


Part 1: Memory Under Pressure
At DualBird, we spent a significant amount of time accelerating Spark query execution on cloud FPGA hardware (AWS F2). The performance gains are real: 10x to 30x faster execution and 50% to 90% lower cost. That's the kind of result you expect from dedicated hardware.
But the part that really surprises people is when we also promise no disk spills from executor memory pressure, no more suffering from hidden data properties such as skews or high cardinality, no more manual tuning and calibration of Spark, and much more. How can that be?
The most consequential part of DualBird’s unique, joint hardware/software approach is that a category of operational problems simply stops existing; not because we patched around them or just made them faster, but because the architecture that generates them is no longer there.
This is the first in a series of posts exploring those changes. We'll start with disk spills.
How Spark handles memory at scale
Spark is built around parallel work. Split the dataset into partitions, run them across the cluster, and push as much concurrency as the hardware can sustain. In a standard Spark cluster, the executor is a JVM process with a fixed memory budget and a set of CPU core slots. The DAG scheduler breaks a stage into tasks, one per partition, and those tasks run on CPU threads in parallel, sharing the executor's memory pool. Spark's fairness rules give each active task a floor roughly near 1/(2N) before spilling and cap it around 1/N of the effective execution pool, where N is the number of currently active tasks. On a typical deployment - say an m5.xlarge with 4 concurrent tasks sharing 16 GiB - each task lands around 1-2 GiB of working memory after JVM overhead and shared structures.
That model is powerful. It's also where disk spills and out of memory exceptions come from. At that scale, spills are not an edge case. They're a normal consequence of many tasks competing for the same memory. In scenarios in Spark where operations cannot spill, out-of-memory exceptions could be thrown, crashing the executor.
Three things make this worse:
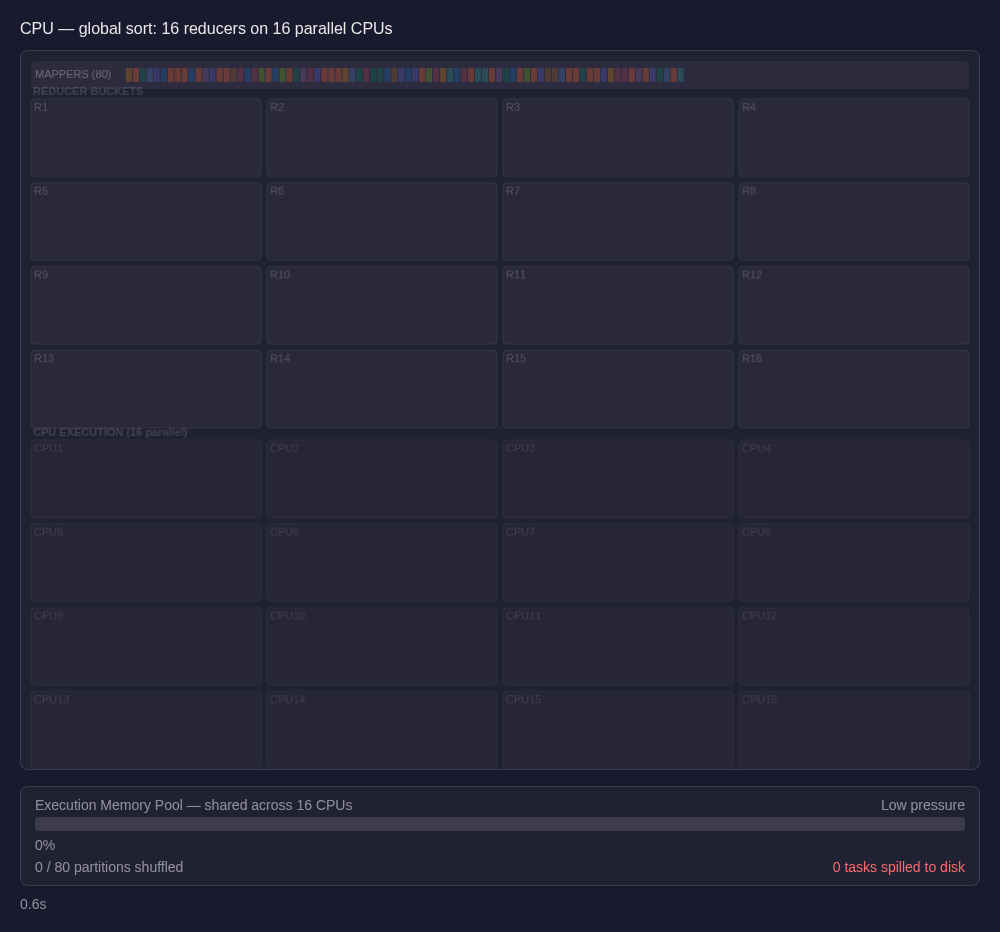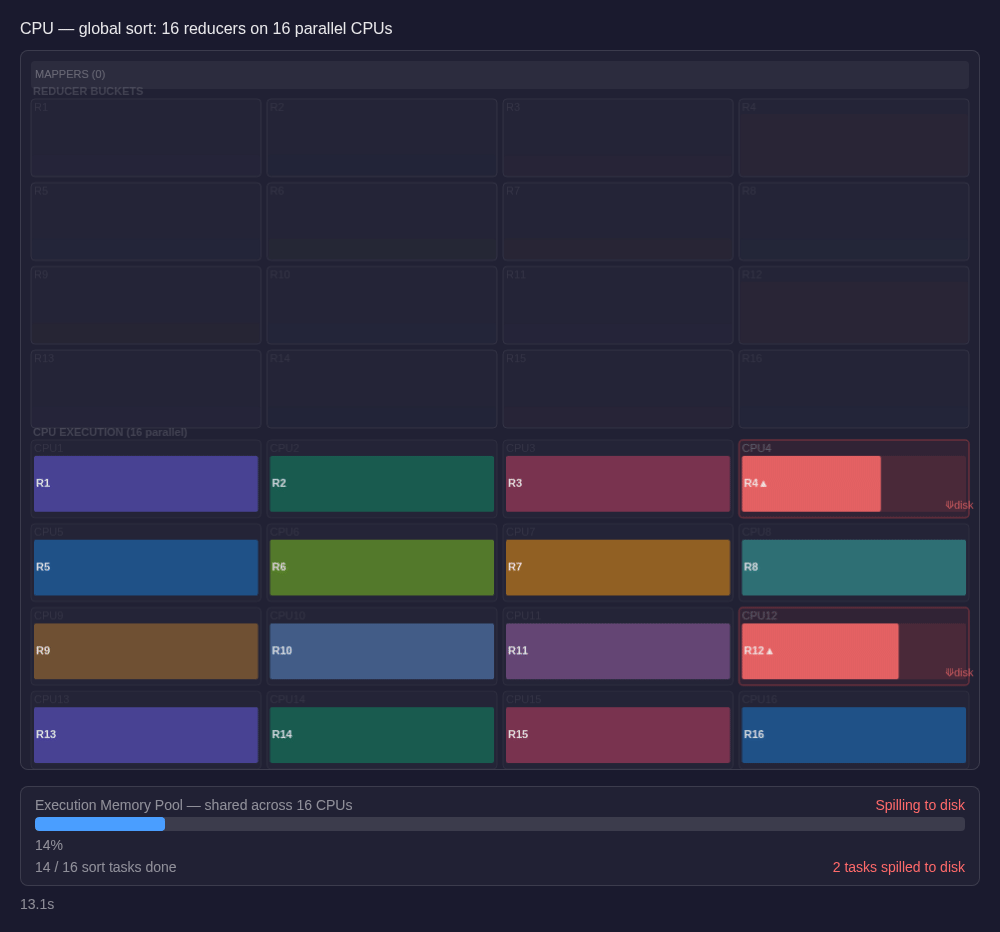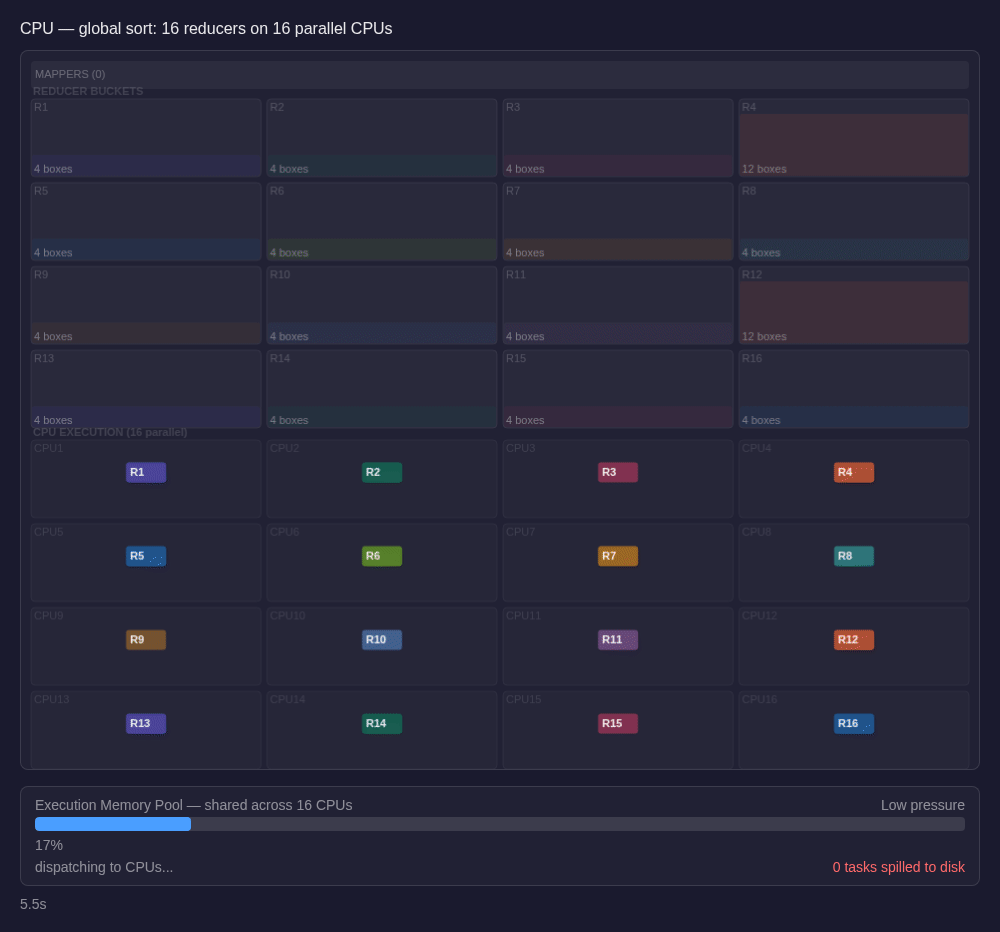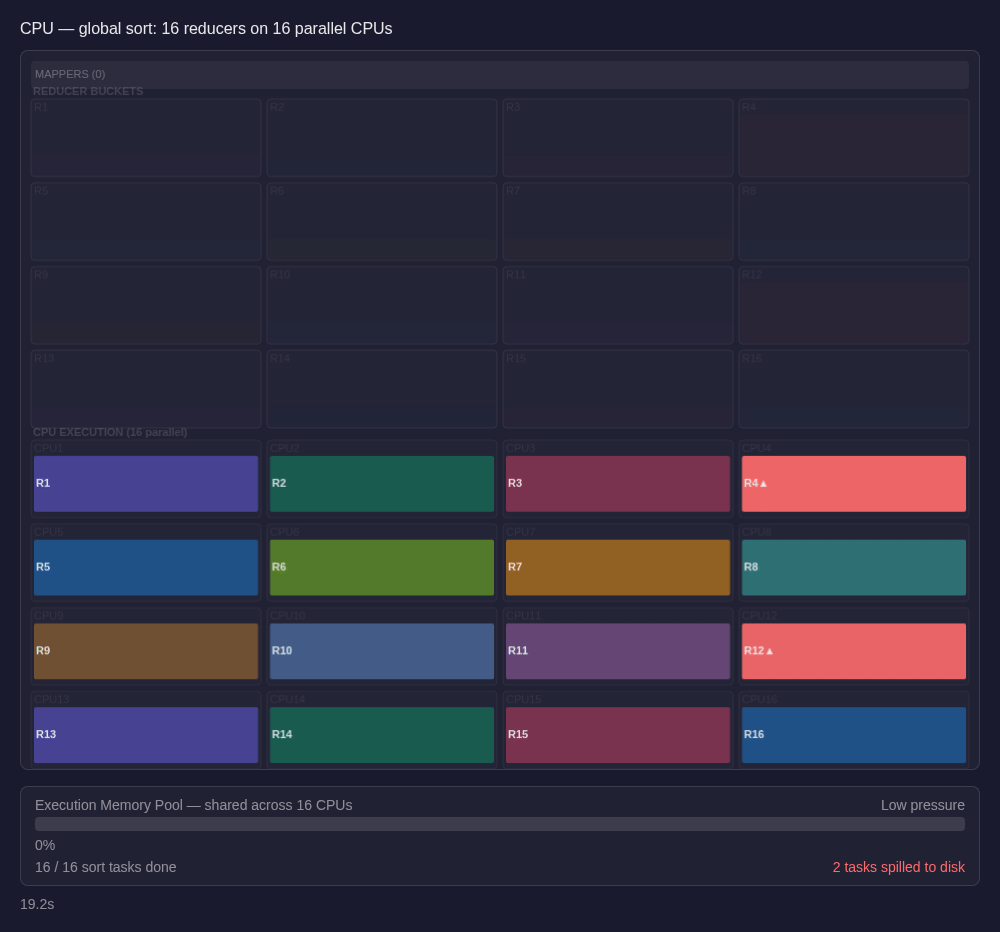
Data skew is the most common trigger. If one partition is much larger than the others, the task processing it needs disproportionately more memory. But the fairness rules don't know about actual partition size, so the task still gets at most 1/N of the pool. The oversized partition exceeds that share and spills. And because the skewed task also takes longer to execute, it holds its memory allocation while other tasks wait at the stage boundary, compounding pressure across the system. There's a lot more to say about skew - we'll dig into it properly in a later part of this series.
Misconfiguration is the second trigger. Wrong partition counts, conservative memory fractions, undersized executors - any of these can push tasks into spilling even on evenly distributed data. The parameter space is large enough that finding the right configuration is often trial and error.
Workload requirements are the third. Some jobs simply need to process large amounts of data per task - target file sizes, output partition constraints, or upstream decisions about how data is grouped. When the working set a task has to hold exceeds its memory share, spills follow regardless of how well the cluster is tuned.
The coordination overhead that comes with managing hundreds of parallel tasks - scheduling, straggler detection, speculative execution - adds its own cost on top.
This is why so much Spark work in production turns into calibration. Teams tune executor counts and memory fractions, adjust partition counts, salt keys, repartition skewed datasets, experiment with dozens of settings, and keep revisiting those choices as data shape changes. A meaningful part of "running Spark well" is not expressing business logic. It is managing the side effects of the execution model.
The usual instinct is to make each worker faster. Rewrite the hot path in C++, use a native columnar engine, replace the JVM with something leaner, maybe do algorithmic tricks. That can help. But it doesn't change the execution model. The same number of tasks are still competing for the same memory, making the system susceptible to spills.
What this looks like in practice: global sort example
Global sort is a useful case because it follows a common ETL pattern of “File scan - Shuffle - Operation - File Write”. This pattern exposes the spill problem clearly, especially when data skew is involved.
A global sort has a few distinct steps, and each one matters here.
First, sampling pass is what lets Spark decide which key ranges should be sent to which reducers.
Then comes the range-partition shuffle: records are redistributed so each reducer (the task after the shuffle) receives one contiguous slice of the global key space. Only after that does each reducer sort its own shuffle partition locally.
The disk spills typically happen in that last step, on the reducer side. Under load, many reducers are sorting at once and sharing the executor's execution memory. When a reducer cannot hold enough rows in memory, it writes intermediate sorted runs to disk and merges them later. If the range distribution is uneven, some reducers receive much more data than others, exceed their 1/N memory share, and spill the hardest. The stage still has to wait for the slowest reducer to finish, creating the stragglers problem.
If you've operated shuffle-heavy Spark jobs in production, the pattern is familiar. You look at the Spark UI and see one or two reducers still running long after the rest of the stage is done, often with heavy spill metrics. Sometimes that really is skew: those reducers drew denser key ranges and had to hold more data. Sometimes it is a data-shape issue instead, like unusually wide rows or a compression ratio that leaves the reducer holding much more materialized data than you expected. Either way, the job bottlenecks exactly where it is already under the most memory pressure. Then the tuning starts: maybe increase the number of shuffle partitions (which may result in smaller output files or additional coalesce operations), maybe repartition upstream to spread keys more evenly, maybe bump executor memory, maybe salt the shuffle keys and try again.
DualBird architecture
We replaced the CPU-based compute inside the executor with a cloud FPGA. The FPGA sits on the same node over PCIe and has its own on-board memory – both HBM (High-Bandwidth Memory) and DRAM, physically separate from system memory and not shared with anything running on the CPU.
The executor buffers a small number of incoming partitions and schedules them to the FPGA, using those FPGA DRAM/HBM memories as the working space for the hardware-accelerated operators. End to end, the executor keeps only a few tasks active at a time, and those tasks advance through a pipelined hardware path on the FPGA instead of across a large wave of CPU threads competing in parallel for the same executor memory pool.
The logical plan doesn't change; the same query produces the same operator tree, dispatched to hardware instead of CPU threads. From Spark's point of view, this is still a normal executor running normal tasks.
The structural consequence is that the executor now keeps only a handful of tasks active at a time, rather than the dozens that are common in CPU-based Spark. Much fewer active partitions on the instance means each one gets a correspondingly much larger share of memory. Where a CPU executor might give each task 1–2 GiB under the 1/N fairness rule, our executor gives each active task access to many gigabytes.

The obvious question is whether trading massively parallel CPU execution for a small number of serial, pipelined FPGA-resident tasks gives up too much throughput. It doesn't. We can afford to keep so few tasks alive because the FPGA is chewing through the work much faster than a CPU executor can. These are not soft cores running software loops. They are deeply pipelined hardware datapaths with direct access to on-board memory, implementing sort, join, aggregations, and other primitives at hardware speed. A single hardware pipeline running tasks serially doesn't just keep up with parallel CPU execution; it far outperforms it. Our benchmarks demonstrate this well, showcasing DualBird’s engine delivering 12-20x faster single-task execution in Spark, compared to a high‐end C++ columnar engine running on a single CPU core.
Why disk spills dissolve
With only a handful of tasks sharing instance memory, the spill math changes completely. For memory pressure to force a spill, those very few partitions active at the same time would need to collectively exhaust all available instance memory; a scenario that is unlikely in all but pathological cases.
Consider data skew, the most common cause of spills in Spark. A skewed partition is dangerous in CPU-based Spark because it needs far more memory than its 1/N share allows - and with dozens of tasks competing, that share is already tight. In our model, a skewed partition simply occupies the hardware pipeline for a proportionally longer period. It doesn't eat into other tasks' memory, because there are so few live tasks memory is allocated dynamically between them. Skew doesn't disappear - the data is still uneven - but it stops being a path to disk spills.
The broader consequence is what data engineers stop doing: no more digging through the Spark UI to understand why one task spilled, no more hand-tuning partition counts and memory fractions to postpone the next spill incident.
Those aren't benchmark numbers. They're hours of engineering time that no longer get burned just keeping the system stable. Future posts in this series will continue to examine how DualBird's architecture eliminates the need to manually tune dozens of Spark configurations.
Global sort example revisited
With our architecture, the sort runs through hardware sort engines in a pipelined execution path. There are no large waves of concurrent tasks competing for memory. A denser key range may occupy the pipeline for a longer time, but it doesn't trigger a spill cascade or force many peer tasks to compete for the same executor-side memory budget while it does so. Overall completion time is sensitive to data volume moving through the pipeline, and not to the worst-case partition under the worst-case memory pressure.
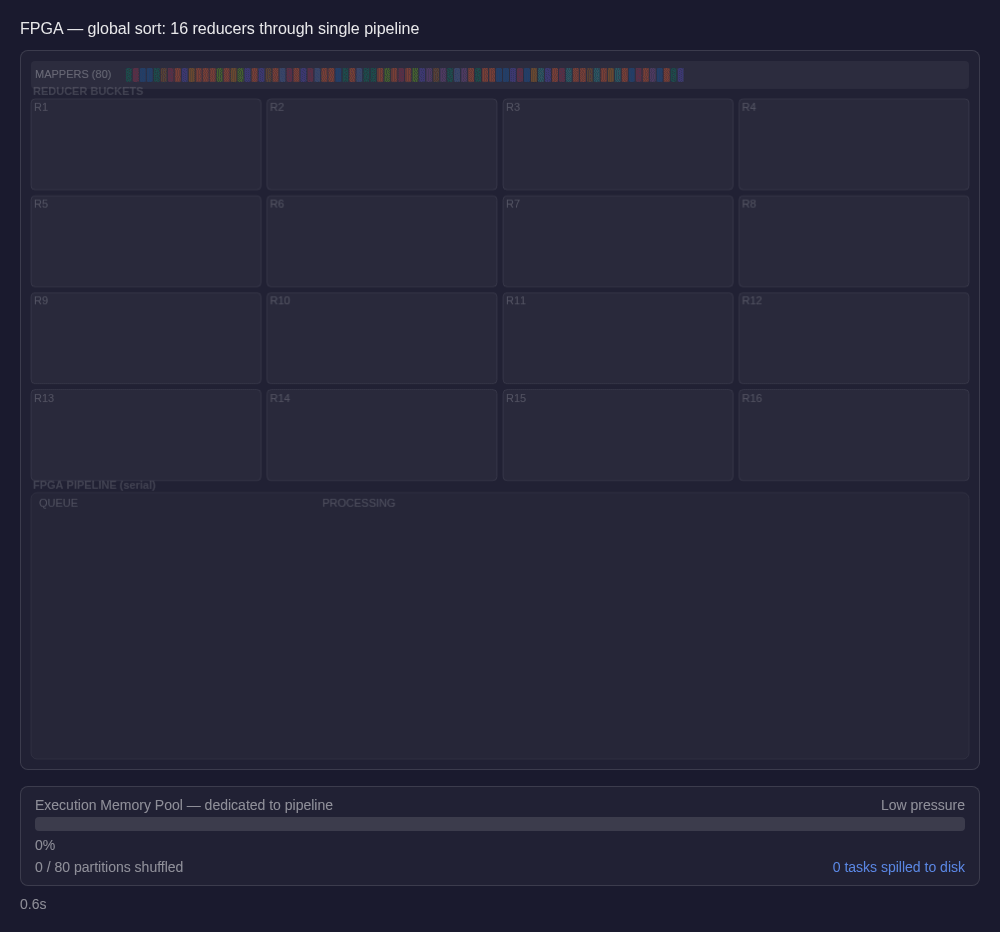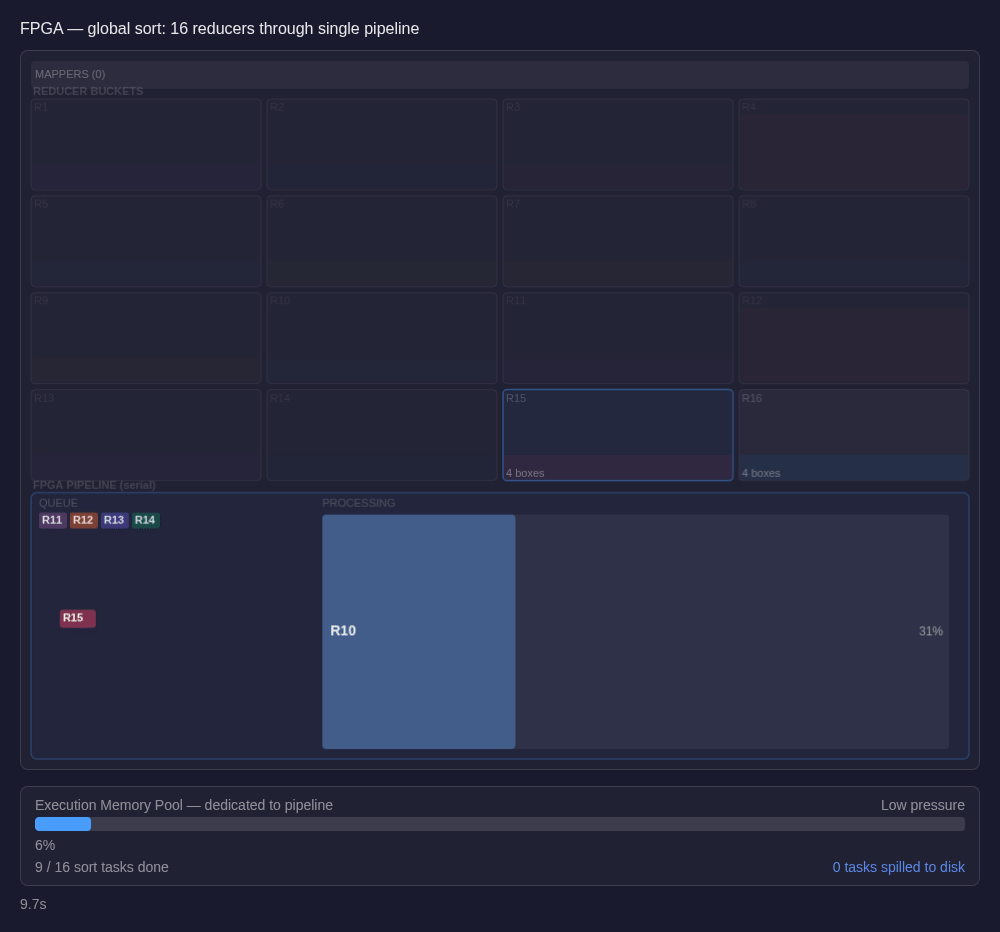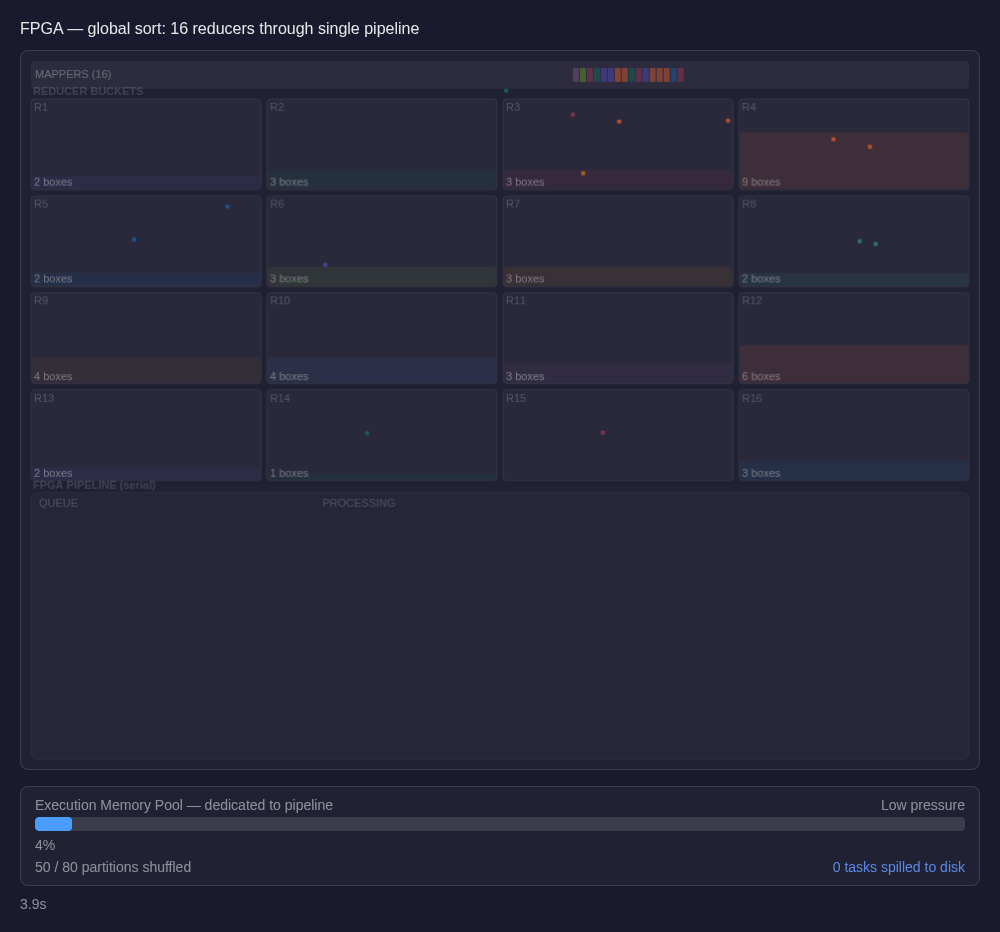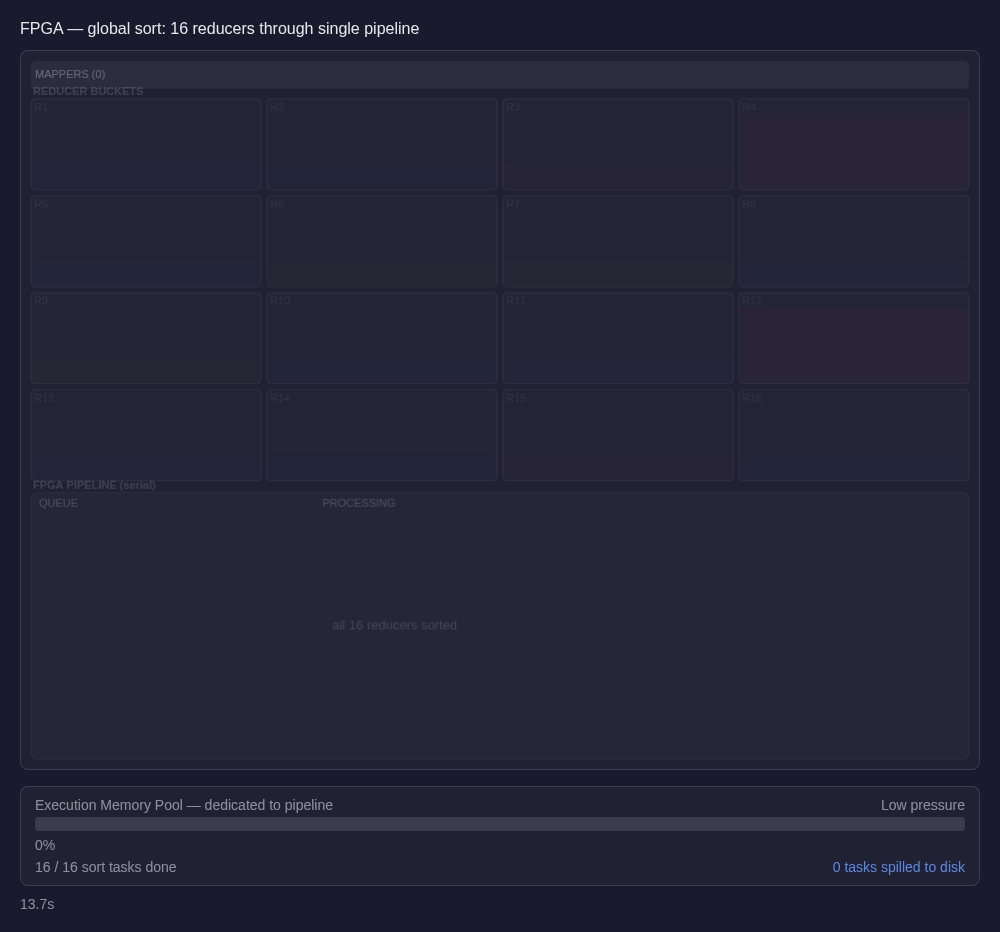
The result isn't just a faster sort. It's a sort that behaves predictably, and that predictability propagates. When one stage finishes in consistent time, the stages downstream from it become more consistent too.
What we actually learned
The headline version of this project is "we accelerated Spark with FPGAs." That's true, but it's only part of the story. Another big change is the execution model.
That changes what operating Spark feels like. Disk spills stop being a normal operating condition. The things that cause them - data skew, misconfiguration, tight memory budgets and large output file requirements - lose their leverage. Teams spend less time investigating spill-heavy jobs because spills are no longer a normal property of the system.
The FPGA path accelerates a defined set of operators - sort, join, aggregation, and others we've implemented in hardware. Workloads dominated by Python UDFs or unsupported operators fall back to CPU and don't see the same benefits yet. Coverage is expanding, and the architectural wins above apply automatically to each new primitive as it lands on hardware.
That's what surprises people. We set out to make Spark faster. What we got was a version of Spark that asks much less of the people running it.
More to come. This is the first in a series on what happens when Spark's execution model moves to dedicated hardware.
Transform your data infrastructure performance with a few clicks
Zero risk, zero effort, incredible results.


